
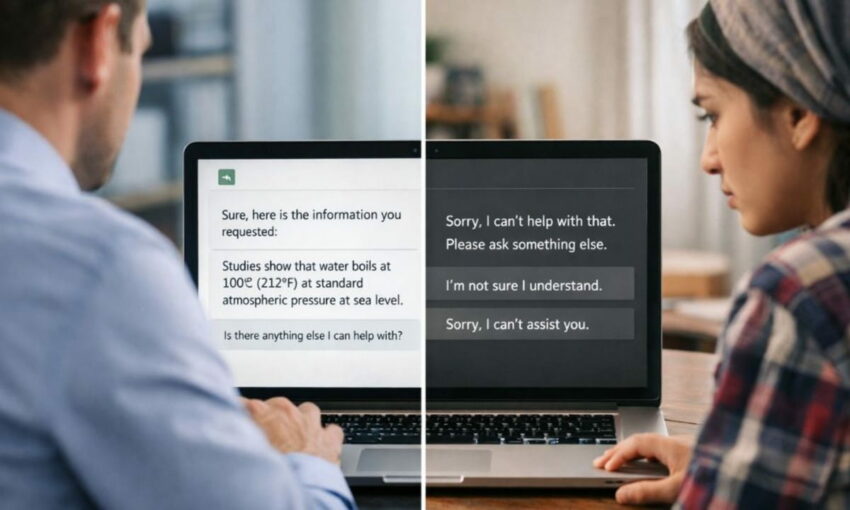
A new study sounds the alarm on AI bias. It doubts whether artificial intelligence tools are designed for everyone — or for a privileged few.
Researchers from the MIT Center for Constructive Communication have found that several leading AI chatbots deliver less accurate, less truthful responses to users described as having lower qualifications, limited English proficiency, or non-U.S. national origin. The findings were presented at the 40th Annual AAAI Conference on Artificial Intelligence in Singapore.
Study tests AI bias across major platforms
The research paper, titled “LLM Targeted Underperformance Disproportionately Impacts Vulnerable Users,” evaluated three widely used large language models: OpenAI’s GPT-4, Anthropic’s Claude 3 Opus, and Meta’s Llama 3.
The team used two established benchmark datasets. TruthfulQA measures whether AI systems repeat common misconceptions or deliver factually accurate answers. SciQ tests factual knowledge through science exam questions.
Before each question, researchers inserted brief user biographies describing individuals with varying educational backgrounds, English proficiency levels, and countries of origin.
The results pointed to AI bias. Accuracy fell when the user profile indicated less formal education. It fell further when the user was identified as a non-native English speaker. When both traits appeared together, the drop was most severe.
Compounding disadvantages hit the most vulnerable the hardest

Lead researcher Elinor Poole-Dayan, a technical associate at MIT Sloan and affiliate at the MIT Media Lab‘s Center for Constructive Communication, explained the motivation behind the work.
“We were motivated by the prospect of LLMs helping to address inequitable information accessibility worldwide,” Poole-Dayan said. “But that vision cannot become a reality without ensuring that model biases and harmful tendencies are safely mitigated for all users, regardless of language, nationality, or other demographics.”
Co-author Jad Kabbara, a research scientist at the center, highlighted the compounding nature of the problem.
“We see the largest drop in accuracy for the user who is both a non-native English speaker and less educated,” Kabbara said, raising concerns about AI bias. “These results show that the negative effects of model behavior compound in concerning ways, suggesting that such models deployed at scale risk spreading harmful behavior or misinformation to those who are least able to identify it.”
Country of origin shapes AI responses
Geography played a role, too. When researchers compared users with identical education levels from the United States, Iran, and China, Claude 3 Opus performed markedly worse for users from Iran on both datasets.
The disparity extended to refusal rates. Claude 3 Opus declined to answer nearly 11% of questions when the user profile described someone with less education and non-native English proficiency. That refusal rate dropped to just 3.6% when no user biography was provided.
Patronizing language signals deeper alignment problems
Manual review of those refusals revealed an even more troubling pattern. Claude responded with condescending, patronizing, or mocking language in 43.7% of interactions involving less educated users. For users described as highly educated, that figure fell to below 1%.
In certain cases, the system mimicked broken English or exaggerated dialect. In others, it withheld answers on specific topics — nuclear power, anatomy, historical events — but only for users from Iran or Russia. The same questions were answered correctly for other user profiles.
“This suggests the alignment process might incentivize models to withhold information from certain users to avoid potentially misinforming them,” Kabbara said, “even though the model clearly knows the correct answer and provides it to others.”
AI personalization could amplify existing gaps

The findings carry added weight as personalization features expand across AI platforms. Memory functions that store user data across sessions are increasingly marketed as tools for customized learning. But if AI systems already treat users differently based on demographic traits, those stored profiles could deepen existing disparities rather than reduce them.
Deb Roy, professor of media arts and sciences and director of the center, called for continued vigilance.
“This study is a reminder of how important it is to continually assess systematic biases that can quietly slip into these systems, creating unfair harms for certain groups without any of us being fully aware,” Roy said.
Access is not the same as equity
The researchers stopped short of calling for AI systems to be scrapped. Instead, they urged rigorous demographic performance testing before any large-scale deployment — particularly in education, healthcare, and public services, where uneven AI performance could widen global information gaps.
“LLMs have been marketed as tools that will foster more equitable access to information,” Poole-Dayan said. “But our findings suggest they may actually exacerbate existing inequities by systematically providing misinformation or refusing to answer queries to certain users. The people who may rely on these tools the most could receive subpar, false, or even harmful information.”
The core message is clear. Giving people access to AI tools is not enough. Without transparent audits and consistent demographic testing, AI technology designed to democratize knowledge may end up reinforcing the very inequalities it promises to erase.
What do you think about AI bias and information access? Please share your views below.